|
I am a first-year PhD student at Tsinghua University. My research interest includes generative models such as Generative Models, Audio Generation and Multimodal Learning. |
|
|
- [2026.04] 🎉 One paper: ControlAudio: Tackling Text-Guided, Timing-Indicated and Intelligible Audio Generation via Progressive Diffusion Modeling accepted by ACL 2026 Main (Oral).
- [2026.01] 🎉 One paper: Omni2Sound: Towards Unified Video-Text-to-Audio Generation accepted by CVPR 2026 (Highlight).
- [2025.07] 🎉 One paper: FreeAudio: Training-Free Timing Planning for Controllable Long-Form Text-to-Audio Generation accepted by ACM MM 2025 (Oral).
- [2025.03] 🎉 Our text-to-audio model is released on Vidu! I developed the text-to-audio and timing-controlled systems that power its audio generation capabilities.
|
|
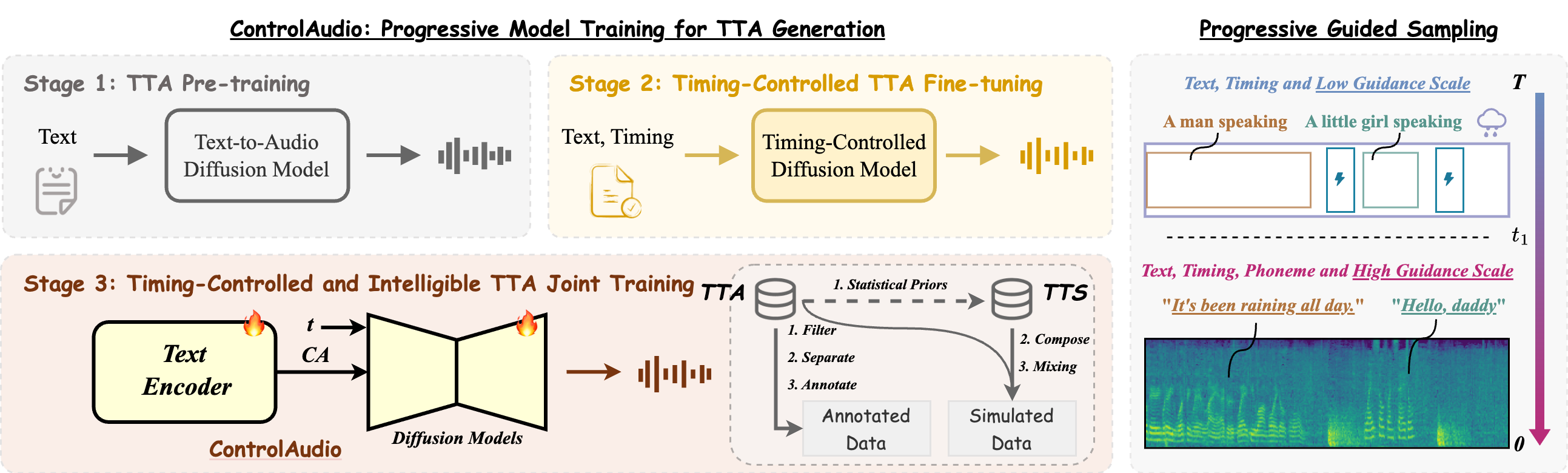
|
Yuxuan Jiang, Zehua Chen, Zeqian Ju, Yusheng Dai, Weibei Dou, Jun Zhu† ACL 2026 Main (Oral) Paper / Website / |
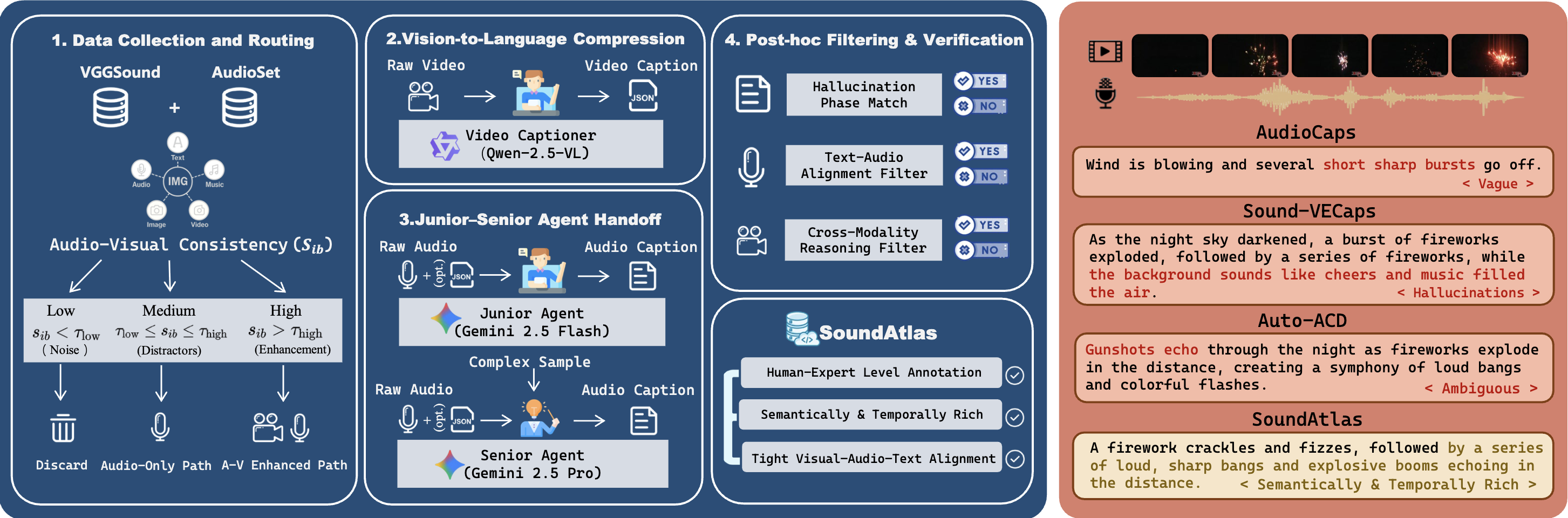
|
Yusheng Dai, Zehua Chen, Yuxuan Jiang, Hongke Qiu, Jian Fei, Jun Zhu† CVPR 2026 (Highlight) Paper / Website / |
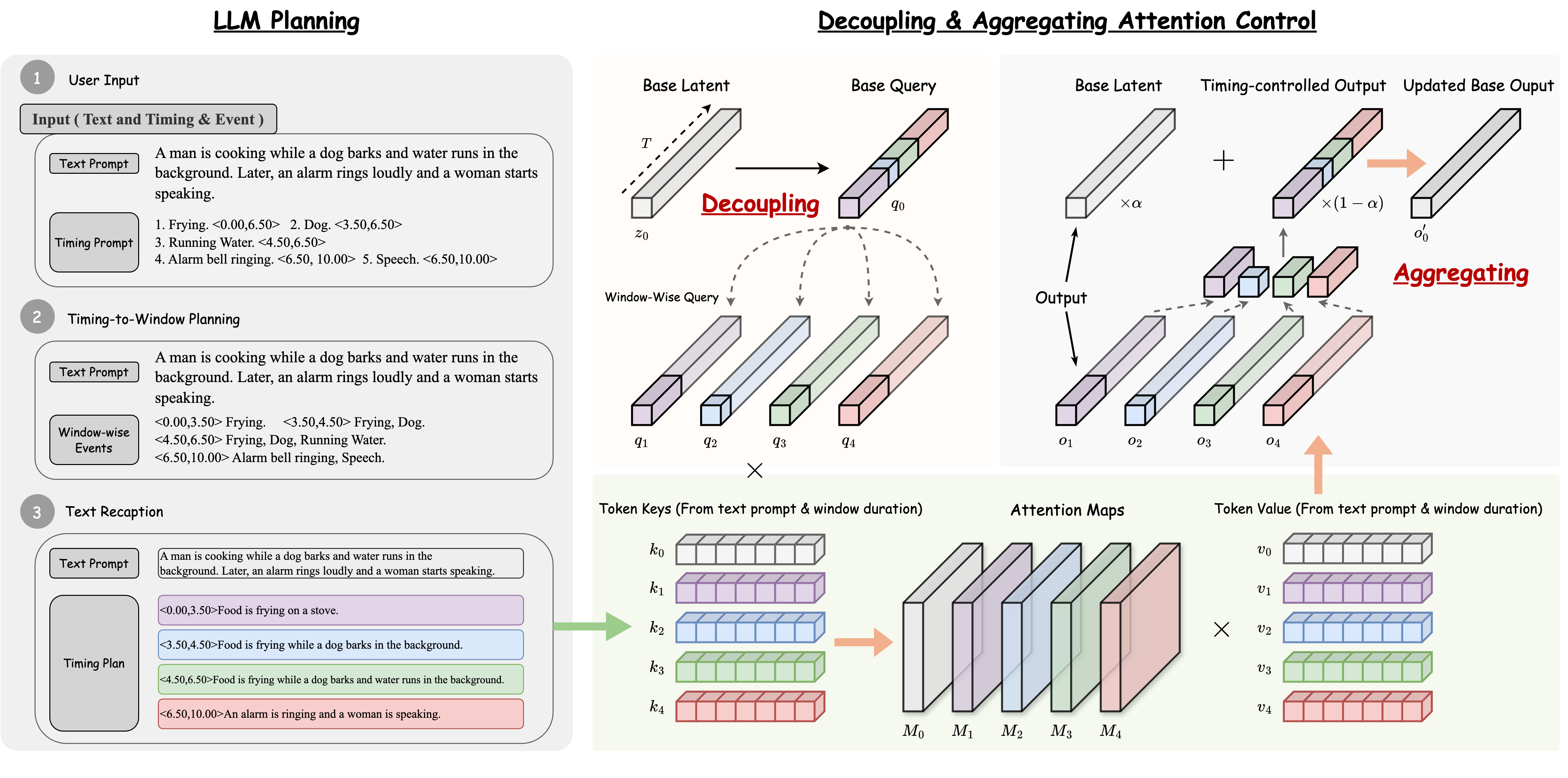
|
Yuxuan Jiang, Zehua Chen, Zeqian Ju, Chang Li, Weibei Dou, Jun Zhu† ACM MM 2025 (Oral) Paper / Website / |